Towards Human Action Understanding in Social Media Videos using Multimodal Models
What is a Lifestyle Vlog?
- Vlogs are also called video blogs, and are very popular in social media channels like YouTube.
- You will see a short span of a video from our dataset, in which a person shows her bedtime activities while also describing them.
- As you will see, there are plenty of visual and textual descriptions of the actions depicted in the video.
- Furthermore, the actions are diverse and done in a specific order: she washes the dishes, plays the piano and then writes in a journal before going to bed.
Why Lifestyle Vlogs for Human Action Understanding?
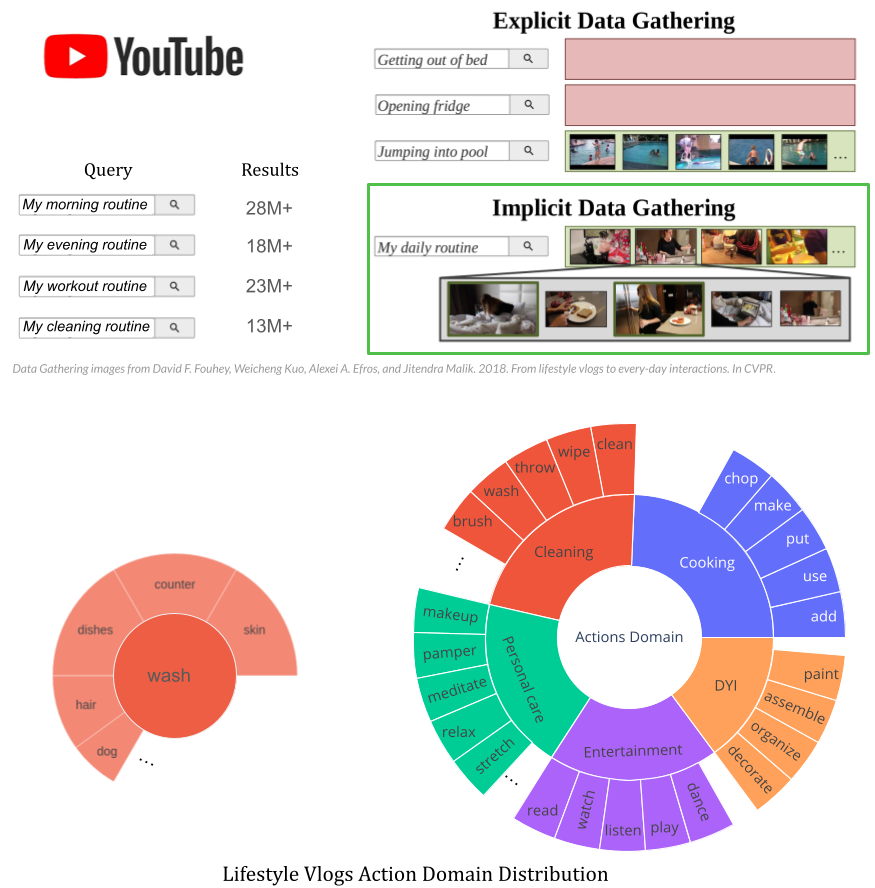
- We gather these vlogs from Youtube by performing implicit data gathering.
We notice that explicitly searching for everyday human actions (getting out of bed, open the fridge) does not provide many results. Instead, we search for queries like my daily routine which contains most everyday life activities.
- High variety of actions in the same video, depicted in their natural order (e.g., wash dishes, play piano, go to bed), with rich textual descriptions of the actions, that provide context (e.g. why and how the action are performed).
- The human actions we obtain from the vlogs are mostly indoor, everyday life activities that can be grouped into 5 main domains: Cooking, Cleaning, Personal care, Entertainment, DYI. Each domain has a long tail of actions. This captures quite well the real life distribution of indoor everyday life activities.
- These lifestyle vlogs are very popular - tens of millions of such videos - can be a very large, actively growing data source.
- Models can learn about the connections between human actions and about human behaviour.
- Downside: The overall plotline of the video is generally aspirational (out of bed at 7am, cup of black coffee, cute fluffy dog) - not representative for all populations. Nonetheless, the individual components (getting out of bed, pouring a cup of coffee) are accurate.
Human Action Datasets & ML Models
IfAct - Human Action Visibility Classification
- Dataset of 1,268 short video clips paired with sets of actions mentioned in the video transcripts, as well as manual annotations of whether the actions are visible in the video or not: out of a total of 14,769 actions, 4,340 are visible.
- Strong baselines to determine whether an action is visible in the corresponding video or not.
- Multimodal neural architecture that combines information drawn from visual and linguistic clues, and show that it improves over models that rely on one modality at a time.
Paper
Poster
Code
WhyAct - Human Action Reason Identification
- New task of multimodal action reason identification in online vlogs.
- Dataset of 1,077 visual actions manually annotated with their reasons.
- Multimodal model that leverages visual and textual information to automatically infer the reasons corresponding to an action presented in the video.
Paper
Poster
Code
WhenAct - Temporal Human Action Localization
- Dataset of manual annotations of temporal localization for 13,000 narrated actions in 1,200 video clips from lifestyle vlogs.
- Multimodal model to localize the narrated actions, based on their expected duration.
- Data analysis to understand how the language and visual modalities interact.
Paper
Poster
Code
CoAct - Human Action Co-occurrence Identification
- New task of human action co-occurrence identification in online videos.
- Dataset, consisting of a large graph of co-occurring actions in online vlogs.
- Several models to solve the task of human action co-occurrence, by using textual, visual, multi-modal, and graph-based action representations.
- Our graph representations capture novel and relevant information, across different data domains.
Paper
Poster
Code